
With AI getting more powerful and sophisticated I wanted to try to have an AI create an auto generated website. I have a couple of hand made niche websites that I monetize with the Amazon affiliate program so I decided I would go for that to me familiar format; a standard blog with reviews about products of a certain category.
Auto generating a website is not hard, but I also wanted the site to perform well, I wanted it to rank high on the search engines and get traffic. If you want your website to generate any search engine traffic you have to build your pages with SEO in mind. Successful SEO is not as difficult as the “SEO professionals” make it out to be.
- The HTML structure need to be properly executed. I.e. Use headlines and paragraphs and make sure any markup is syntactically correct etc.
- Scripts and CSS needs to be optimized and placed correctly for page load speed.
- The content of the page needs to contain relevant keywords and LSI keywords to rank for. These keywords must also makes sense with regards to the topic. The content also need to be unique and not copy pasted from somewhere else. Moreover, the content must make sense in a grammatic and semantic point of view.
Step 1 and 2 are very easy for a computer program to adhere to. If you write the program you can assure that the structure and syntax you generate is correct and that the JavaScript and CSS is correctly implemented.
Step 3 however, this is where the challenge lies. Before AI and specifically NLG it was virtually impossible to write a program that could generate text that was indistinguishable from what a human would write. This has changed as deep learning and natural language generation has evolved. The last couple of years there has been a lot of hype over what the OpenAI GPT machine learning model can do, and I believe this hype is somewhat justified considering what I have seen the model do. So I thought that theoretically you should be able to auto generate websites and it’s content with the help of GPT-2. I wanted to test if it is also practical with regards to the computing power and time consumption I believed it needed, so I started this project I called AIWriter.
Creating the Framework for an Auto Generated Website
The landing page for the website is actually made manually in PHP. It is a simple blog site were the landing page consists of a menu and a list of blog post titles with accompanying excerpts that you can click to be taken to the post page.
The landing page script simply takes all available posts from a database. The database is populated by the Java web scraping program and the text generating Python script which I will cover in more depth later in this article.
The post pages are generated with a single PHP script which given the title the user clicks on fetches everything it need from the database. The scraper have fetched images and some other data like specification, price and product description. The text generating script using AI will have produced the paragraphs for the page which are also available from the same database.
Considerations when Finetuning a Deep Learning Model to Generate the Best Results
The latest iteration at the time of writing this is GPT-3 but when I started this project GPT-2 was the current version. The models comes in several sizes, the largest has 1.5 billion parameters and requires a really powerful computer to operate. As I did not want to spend a fortune just to test my project I went for the medium sized model, the 355M model. The medium model can be trained and run on the Google computing services that offers powerful cloud computing equipped with for example the Tesla T4. Training models takes more resources than running them, I got the large 744M model to run but I ran out of memory when trying to train it.
I also tried to use the web interface that OpenAI offers for the 1.5B model but it is more of a demo trained on a diverse corpus of texts and it yielded poor results for my use case.
So the conclusion is that the model has to be trained on material that is relevant. In this case it needs to be trained with reviews and also texts about the products that was going to be reviewed. After some product and keyword research I decided on making a review site for flashlights. The decision was based mainly on that the competition was relatively low and the fact that flashlights can be very diverse meaning you have many options to create a diversified collection of articles which is very good when trying to rank your niche site.
First I tried to train the GPT model with more generic data. I used texts from famous review sites and information from Wikipedia about flashlights etc. This gave better results but quite often the generated text was incoherent and included text about the wrong product.
My third attempt was to train the model for each product it was going to write a review of. Training a model enough steps and with a large enough corpus takes time. So having to re-train it for each article could be very time consuming and require a lot of manual work. I decided to automate both the collection of training material and the training itself.
Automatically Collecting Training Material for GPT
First step is to decide where to retrieve the training material. Amazon has a lot of information about their products and even better they have user made reviews of the products. Wiki pages also offer some good facts about flashlights and things related such as batteries, lenses, and optic science.
I manually collected text from different wiki sources about flashlights, but I wrote a simple Java program to crawl and scrape Amazon. The program would first select a suitable product by sorting by highest rating but also by number of user reviews. During my tests I came to the conclusion that anything less than 20 000 characters worth of training material would not yield good results. So the products that was suitable needed a couple of hundred user reviews to be suitable for auto generation.
After a product was selected the Java app simply scraped all content available on Amazon for that particular product. Training a deep learning model can be quite sensitive and if you train it on bad material the result is often also bad. So the text collected needed to be cleaned up, especially the user made reviews could contain a lot of text that was not good for deep learning.
To achieve a good cleanup the program parsed and tokenized the text which was then run through two passes of NLP. Grammatically or semantically bad chunks would be disposed and as a bonus it could also extract keywords and rank them. The keywords would come in handy in the generation step which I will cover in a bit. After the text has been cleaned up, the program uploads it to a web server which stores it in a database.
Collecting Product Information and Resources
Since the Java program is already scraping everything it can find for the product it will get a lot of additional resources that can be used when generating a review. So with no additional effort, product images, description and specification is also uploaded and stored in database the same way that the cleaned training text was.
I mentioned before that for a page to rank well on search engines the content of the page needs to be original and that you should not copy paste. However, a product specification can not really be re-written, it is what it is. So in this case I break one of the SEO rules because I think it is more important for readers of the review to get this information.
One thing I did that would add value over the original specification and description was to add links to Wikipedia for technical terms such as LED, Lumen, Kelvin etc. This was done after the cleaning and NLP keyword ranking by referencing a list of all technical terms related to flashlights I could think of. If a keyword was found in the reference list it was replaced with a wiki link.
Finetuning GPT-2 to Generate Good Product Reviews
Now that all the training text has been collected, cleaned and parsed it is time to train the GPT-2 355M model. For this I used a Python notebook on Google Colaboratory. I actually used one script for both training, generation and publishing, but I will talk more about the two latter steps later.
My goal is to make the GPT-2 generate coherent and relevant text that looks like a human had written it. Equally important was that I wanted the text the be a sort of consensus of what users had written in their reviews, the information was meant to be true and not misleading.
To meet my second goal I decided that I needed to train the model on each separate subtopic of the review, before I did that all the subtopics had an inclination to look the same. This would of course require even more time for finetuning, but all the training text was already collected so I only had to do a bit of analysis and select the best parts.
I had to run another pass of NLP to finetune the model for each subtopic I wanted it to write about. So I used NLTK and Yake to extract only reviews that mentioned the keywords in each separate subtopic I wanted the AI to write. I wanted 3-5 subtopics and a summary for each page, the keywords for each had already been decided in the previous NLP pass.
So for example to finetune GPT-2 to write the summary I used the keywords from the title of the page. The script goes through all user made reviews and selects the ones that matches the keywords the best. These reviews are then finally used as training material to fine tune the deep learning model.
I think this solution, although time consuming, was needed to create text that actually is true. This way the consensus of the most common characteristics of the product will be used and it will also be a consensus of the opinions of those characteristics. A sort of AI powered meta review, which was exactly what I was going for when I started the project.
Auto Generating Website Content with GPT-2
When the finetuning for a specific part of the review is complete it is time to use GPT-2 to generate text for it. When generating text it is best to give the model a prompt about what it should write about. The script already has the perfect prompts, the sub headings.
After the text is generated it is uploaded to the web server and stored in the database. The finetuning and generation is done for each part of the review using the topic and subtopic as keywords for the training and as text for the title and subheadings.
When this is done the web page is completed as we had already created the indexation, images, price and product description in the scraping step.
The Result of Putting it All Together
You can take a look at the results on https://flashlights.junglesentry.com/
This site had zero exposure before this projects, in fact it was made specifically for it. All I have done is to add the site in the Google Search Console, no additional SEO work has been done.
So how did it go? What are the results? Well, in terms of ranking for keywords on google it currently has about 85+ keywords with a position of the first page of search (rank 10 or less)

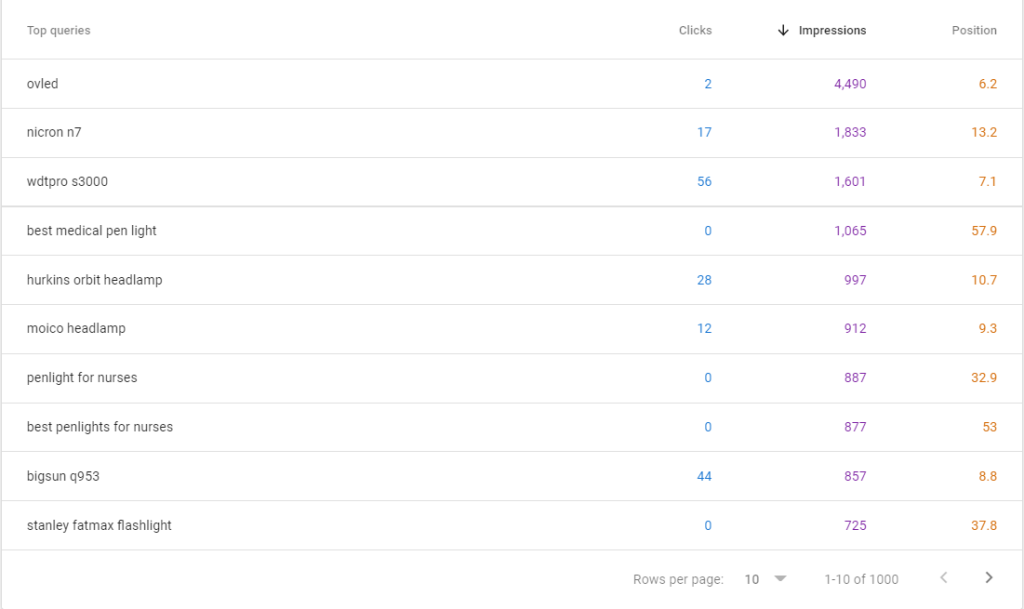
A more finetuned version where I removed the copy paste of user reviews (remember step 3 of the SEO rules?) and created a bit more diversification of the subtopics for each AI meta review: https://junglesentry.com/review/
And this is what happened when I added the review section to the junglesentry.com site on september 30th 2020. This site was a couple years old and was already ranking quite well for a niche affiliate site.
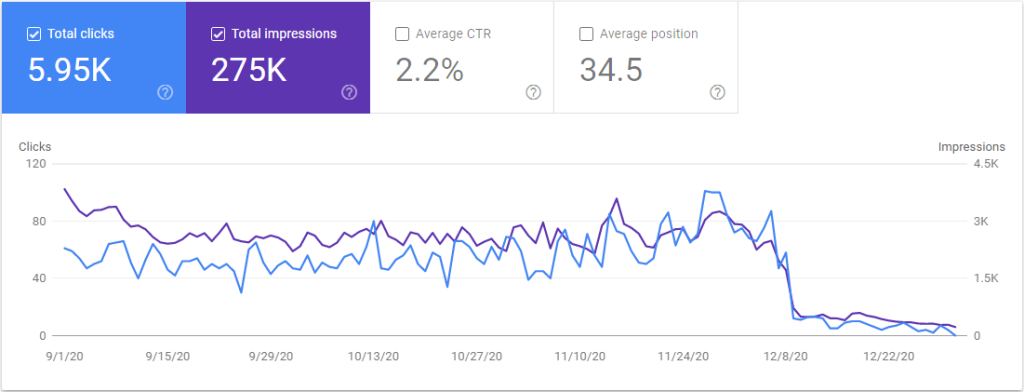
Google did not like that! Clicks and impressions was initially rising but after 3 months the whole site lost 95% of it’s traffic.
I removed the copy pasted user reviews but the site has still not recovered and I don’t think it will.
Why the flashlights site has not taken a similar hit I can only speculate. The flashlights site is much smaller and probably goes under the radar.
Final Thoughts on Auto Generating Websites
First I want to say that I am pleased with how the system works and how it actually creates a meta review that is true to the consensus of what verified users think.
However, the quality of the generated texts is not good enough. I think that this is mostly due to the limitations I had for this project. If I could have used the GPT-3 175B model the quality produced should be much better. Not many people have access to hardware that could do this and additionally the time it would take to finetune for each subtopic would be to much to be practical.
But maybe somewhere in between would give satisfying results..
Pretty! This has been a really wonderful post.
Many thanks for providing these details.